Operating System
操作系统基本概念学习。
概述
基本术语
OS的基本工作:
- 协调程序(进程)
- 分配资源
kernel v.s. shell:
- kernel是OS内核,包含OS所有核心功能的实现
- shell将kernel包裹在其中,是面向用户的应用。
并发 v.s. 并行:
- 并发:一段时间内多程序执行,由OS调度(单CPU)
- 并行:一瞬间多程序执行,由多CPU实现
OS kernel基本特征:
- 并发
- 异步
- 共享
- 虚拟
OS启动过程
OS也是软件,存储在硬盘中,在物理设备启动时被加载进入内存运行,流程:
- 物理设备上电
- POST:加电自检
- BIOS(Basic IO System)检测外设
- bootloader将OS加载入内存
- 跳转至OS内存起始地址,开始运行
程序/硬件与OS的交互
为保证安全性,应用程序没有权限直接访问硬件设备,需要通过OS作为中介完成访问,实现程序和硬件的隔离。
交互分三种:
- 系统调用:应用程序向OS发出调用硬件的请求,同步or异步
- 中断:硬件向OS发出请求(例如键盘输入),异步
- 异常:应用程序产生的非法/错误状态,异步
同步与异步:
- 同步:应用发起请求后等待至结果返回(阻塞)
- 异步:应用发起请求后继续进行其他工作(非阻塞)
系统调用
系统调用连接了应用程序与操作系统,可视为用户态和内核态的接口。
用户态和内核态描述的是CPU的状态:
- 用户态:CPU只运行低权限指令
- 内核态:CPU可运行任何指令
系统调用通过系统调用表和调用号映射对应的服务。
中断处理
一旦产生中断,OS通过中断表查询对应的处理方式。中断表记录了中断类型(中断号)与中断服务地址映射关系。中断处理由软硬件两方面配合进行。
硬件:
- 产生中断标记
- CPU由标记生成中断号
- OS由中断号查中断表确定中断服务地址
软件:
- 保存当前状态(现场保护)
- 运行中断服务
- 清除中断标记
- 恢复之前状态
异常处理
流程:
- 产生异常编号
- 现场保护
- 异常处理(进程停止or重复执行产生异常的指令)
- 现场恢复
OS物理内存管理
OS通过对物理内存进行管理,为了实现如下几个目标:
- 抽象:使用逻辑地址空间描述内存
- 保护:程序彼此之间使用独立的地址空间
- 共享:程序可以访问相同一块物理内存
- 虚拟化:提供更多地址空间
描述内存使用如下两个定义:
- 逻辑内存:程序拥有的内存使用范围(一维、线性)
- 物理内存:真实的硬件内存空间
逻辑内存一般大于物理内存,由MMU(内存管理单元,位于CPU中)进行逻辑内存向物理内存的映射,映射通过映射表实现,映射表由OS在映射前生成。
内存分配分为连续内存分配和非连续内存分配。
内存分配会导致产生内存碎片,内存碎片分为内碎片和外碎片。
- 内碎片:分配给程序的内存块中产生的无法使用部分
- 外碎片:整个物理内存中产生的无法使用部分
连续内存分配
将内存中一段足够大的连续区域分配给单个程序。有以下几种分配算法:
- 首次适配(first fit)
- 最佳适配(best fit)
- 最差适配(worst fit)
首次适配
从低地址向高地址遍历内存,将第一个满足程序内存要求的空闲内存块分配给程序。
要求:
- 空闲块按地址大小排序
- 内存回收后相邻空闲块要合并
优点:
- 实现简单
- 回收后产生大空闲块
缺点:
- 产生外碎片
最佳适配
将最小的满足程序内存要求的空闲内存块分配给程序。因此空闲块大小最接近要求。
要求:
- 空闲块按大小排序
- 回收后相邻空闲块要合并
优点:
- 不分割大空闲块
- 对小内存需求友好
- 最小化外碎片生成
缺点:
- 产生太多小碎片
最差适配
将最大的满足内存要求的空闲块分配给程序。与最佳适配正相反。
要求同最佳适配。
优点:
- 避免小碎片
- 对中内存需求友好
缺点:
- 产生外碎片
- 拆分大空闲块导致对大内存需求不友好
碎片整理
为了缓解碎片问题,提高内存使用率,有两种碎片整理方式:
- 压缩式:调整程序在内存中的位置,尽可能将碎片相邻后合并
- 交换式:将某些暂时不执行的程序保存至硬盘,腾出空间给其他程序,其他程序运行结束再从硬盘读回内存
压缩式存在问题:何时调整程序位置,开销太大
交换式存在问题:交换哪些程序,何时换入换出
非连续内存分配
非连续内存分配的好处是有效解决了碎片问题。引入分段(segmentation)和分页(paging)机制实现逻辑内存和物理内存之间的对应。
分段
段(segment):一个程序根据根据不同功能分成几个不重叠的部分,彼此内存不会相互占用,这些不重叠部分所占的内存称为段。每个段的长度不一定相同。
分段:将程序逻辑内存按段映射至物理内存中非连续的内存块。例如某程序$\mathbb{P}$按功能分为$a_1,a_2,a_3,a_4$四个段,根据映射关系分别对应物理内存中非连续的四个段$b_5,b_7,b_3,b_6$。
分段寻址机制
使用段号+段内偏移的方式对段进行编码。为了实现逻辑内存到物理内存的映射,使用段表进行映射,由OS对段表进行维护。段表记录了逻辑段号和物理段号的映射关系,以及偏移限制,分段寻址流程为:
- 确定逻辑段号和偏移
- 查段表,确定对应的物理段号以及偏移限制
- 检查偏移是否满足偏移限制
- 若满足限制,访问对应物理内存
分页
比分段更实用的方法是分页。在分页寻址中使用页号+页内偏移表示某个地址,与分段不同,物理内存和逻辑内存中页的大小是相同的,每个页拥有相同的最大偏移量,所以页是对内存进行大小相同的分块。物理内存中的内存块称为帧,逻辑内存中的内存块称为页。
通过页表实现页与帧的映射,OS负责维护页表,页表记录了逻辑页号和物理帧号的对应关系。
分页寻址机制
流程与段寻址类似,但是不需要检查偏移限制,因为使用页进行内存管理,最小粒度都是一页的内存空间:
- 确定逻辑页号
- 在页表中寻找对应帧号,并判断物理内存中是否有对应帧号的内存块
- 若有对应帧号,完成寻址;否则抛出缺页异常
存在位(resident bit):页号中某位称为存在位,该位为1表示物理内存中有对应帧,为0表示缺页,抛出缺页异常。
一个例子,假设页号第二位为存在位:
| No. | page num | frame num |
|---|---|---|
| 1 | 100 | 00000 |
| 2 | 011 | 00100 |
第一个页号由于存在位是0,因此会抛出缺页异常;第二个页号存在位是1,根据页号3(011)找到对应帧号为4(00100),因此寻址成功。
页表存在的问题:
- 页表太大,占用大量空间
- 内存访问开销大(因为页表同样放在内存中)
为了缓解页表的问题,采取两种方案:
- 缓存:TLB
- 间接访问:多级页表
Translation Look-aside Buffer,TLB
TLB是一个放在CPU中的缓存,其中存储了最近访问的页表项,因此对于经常需要查找的页表项可以直接从缓存中获得,无需访问内存造成更大时间开销。
工作流程:
- 确定逻辑页号
- 在TLB中查询对应物理帧号
- 若查询到,则直接访问对应内存;若查不到,再去查页表,之后将对应项更新到TLB中
多级页表
将逻辑页号拆成多部分,建立多个页表。一个页号$n$从高位到低位拆分为$n_1,n_2,\dots,n_i$共$i$段,分别对应$i$个页表,从第一段开始,在前一级查找页号$n_{k-1}$对应的值作为下一级的基址,下一级使用基址加上当前级页号$n_k$查找更下一级的基址,直至最终确定物理地址。
多级页表的好处是,树状的页表结构无需记录存在位为0的表项,从而在早期进行剪枝,节省了页表存储开销,以时间换空间。
反向页表
传统页表建立由页号至帧号的映射,联系了逻辑内存和物理内存,页表项数量是由逻辑内存大小决定的。由于逻辑内存大于物理内存,页表项会占很大空间。
反向页表希望由物理内存决定页表项,只记录物理内存存在的页号-帧号映射,从而减少存储空间。
实现方案有如下几种:
- page register,页寄存器
- associative memory,关联存储器
- hash技术
页寄存器记录“反向映射”,即帧号-页号映射关系;关联存储器与页寄存器思想类似,位于CPU中,但是硬件复杂度很高;hash技术通过构造hash函数$f=h(PID,p)$,由进程号和页号计算帧号完成映射。
虚拟内存
虚拟内存主要用于解决当物理内存大小有限,如何尽可能让更多、更大的程序高效运行在有限内存中的问题。
可以分成三个方面:
- overlay,覆盖技术
- swaping,交换技术
- 虚存技术
覆盖技术
覆盖技术考虑的场景:早期小内存,大内存占用的程序如何运行。这种情况下无法将程序所需的数据和代码一次性全部读入内存。
覆盖技术通过将程序分为很多程序块,将没有调用关系的程序块按执行时间先后访问同一内存,暂时不用的块放在外存中保存。
例子:
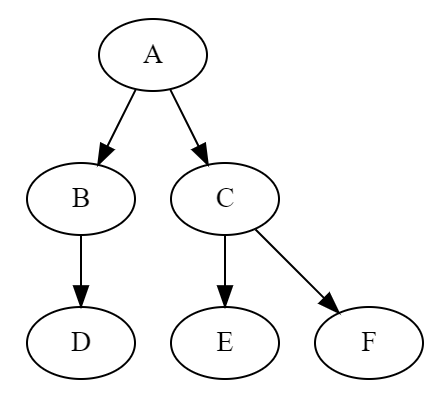
A为主程序,其下分为多个模块,形成树状结构。每一层子程序彼此之间都没有调用关系,我们可以如此设计它们在内存中的分配:
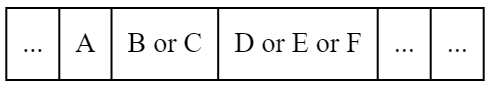
其中B、C和D、E、F所用的内存是覆盖区,按照时间先后顺序运行子程序,内存可以被覆盖重新使用。内存分配的方法不唯一,只要满足没有彼此调用关系的子程序共享覆盖区即可。程序分块往往需要人工设计实现,成为覆盖技术的较大问题。
交换技术
交换技术考虑的场景:多程序,小内存的情况。这种情况下为了让每个程序尽量能高效运行,需要以整个程序为单位,将其在内存与外存间交换存储。程序运行时载入内存,不运行时存入外存从而腾出内存空间给其他要运行的程序。交换过程由OS实现。
交换技术要解决的问题:
- 何时进行交换?
- 准备多大的交换区?
- 程序能换回内存中原来所在的地址吗?
虚存技术
虚存技术可以看做对交换技术的改进,交换技术以整个程序为单位进行交换,而虚存技术改为以段/页为单位进行管理。
基本特点:
- 只将部分即将执行的段/页载入内存运行
- CPU所需不在内存中,引发缺段/页异常,OS将所需载入内存
- OS将暂时不运行的段/页存入外存并释放内存
虚拟页式内存
使用页为单位的实现虚拟内存最常见。OS将即将运行的页放入内存,运行如果需要其他页,引发缺页异常,然后OS将所需页加入内存,同时OS将暂时不用的页放回外存。
对页表项的扩充:

- 访问位:记录该页是否被访问(读/写)过,用于页面置换
- 修改位:记录该页是否被修改过,从而决定回收时是否要保存到外存中
- 保护位:记录该页允许的操作(读/写/执行)
- 驻留位:记录是否存在对应物理地址,用于产生缺页中断
缺页处理的简单流程:
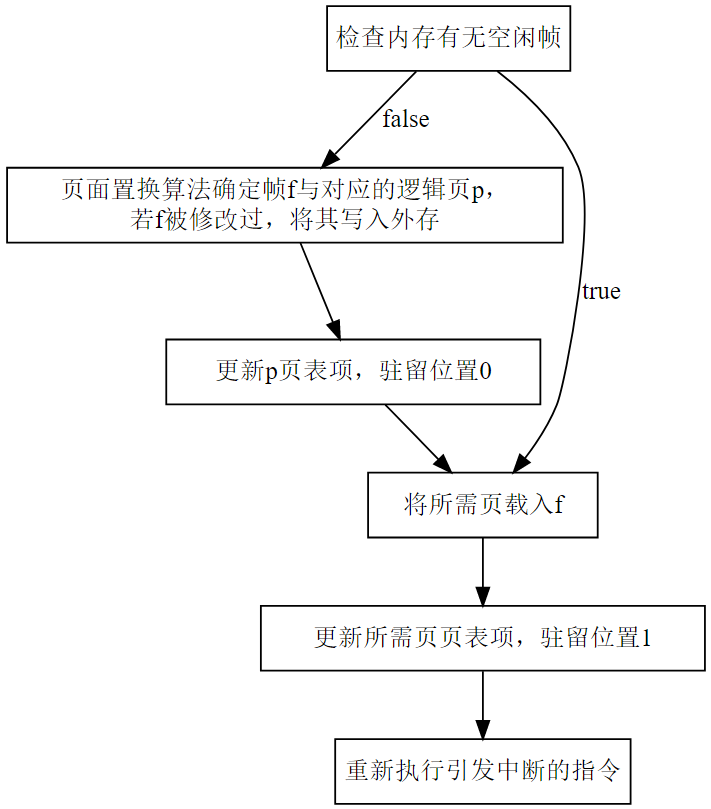
对虚拟内存的性能可以用EAT(effective memory access time)进行评估:
$$
EAT = pt_m + (1-p)t_d + (1-p)qt_d
$$
其中:
- $t_m$:访问内存的时间开销
- $t_d$:访问硬盘的时间开销
- $p$:页表命中概率
- $q$:某页需要写入硬盘保存的概率
局部页面置换算法
虚拟内存实现过程中出现需要将暂时用不到的某些页置换到外存中存储,如何确定这些页?需要页面置换算法。
这里先介绍局部页面置换算法。
最优页面置换
理想情况下,假设我们能计算所有逻辑页下次被访问前的等待时间,即可将等待时间最长的页换出。但是这是不可能的,只能作为一种理想的指导思想。
FIFO
使用FIFO先进先出队列选择置换页,结构简单。FIFO队列将最早加入内存(存在内存时间最长)的页拿去置换。最旧的页始终位于队头,新页位于队尾,置换时队头出队,新页进队。
实际中FIFO虽然结构简单但是性能很差,还会引起Belady现象。
Belady现象:分配的物理内存越多,缺页反而越频繁。
LRU,least recently used,最久未使用算法
基于FIFO,我们做一些改进:FIFO只记录“存在”内存中页的时间长短,因此很可能将常用的页置换出内存。LRU改之记录页距上次被访问的时间长短,队头记录最久未使用的页,队尾记录刚被使用的页。
为了维护LRU,每次完成一次页的访问,该页进队,然后删去队列中之前出现的该页(完成了访问时间的更新);每次页面置换时将队头出列作为置换页。
时钟页面置换算法
LRU开销太大,对此,时钟页面置换算法使用环形链表对LRU进行近似。
使用访问位简单记录页被访问的情况。
用环形链表记录内存中的所有页,用一个指针指向最早访问的页。新页加入内存,访问位置0;一旦访问到记录的某页,访问位置1。
发生缺页中断,检查指针所指页,若访问位为1(表示不久前访问过),将其置0并指向下一个页,直到找到一个页访问位为0(表示很久未访问),将该页置换为新页,之后访问位置1,然后指针指向下一个页。
二次机会法/改进的时钟法
对时钟法进行一些改进,引入脏页位(dirty bit),表示某页是否被写操作过。同时使用访问位和脏页位判断是否某页要被置换。
所谓“二次机会”是指给予经常进行写操作的页更多的不被置换的机会。在使用时钟法时,根据如下转换表决定当前指针指向的位如何更新:
| 访问位 | 脏页位 | 访问位(新) | 脏页位(新) |
|---|---|---|---|
| 0 | 0 | replace page | |
| 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1(二次机会) |
LFU,least frequently used,最不常用法
LFU记录所有物理内存中页的访问次数(使用计数器),发生缺页异常时置换访问次数最少的页。