Pytorch Tips
Pytorch基本用法记录。
计算图
计算图是自动微分实现的一种流行的方式,将数学运算按照顺序组织成一张无环图,节点记录运算算符,边记录数据流。通过对图节点的深度遍历可以前向计算每个节点的计算结果,然后递归地计算每个节点的梯度,最终可以根据需要,借助链式法则计算任何参数的梯度。
计算图定义前向和反向传播有两种方式:
- 先创建前向计算图,然后在同一张图上反向计算梯度
- 先建立前向计算图,然后根据相反的拓扑关系补充新的节点,在原图后建立反向的计算图计算梯度
第一种方法比较常见。例如:
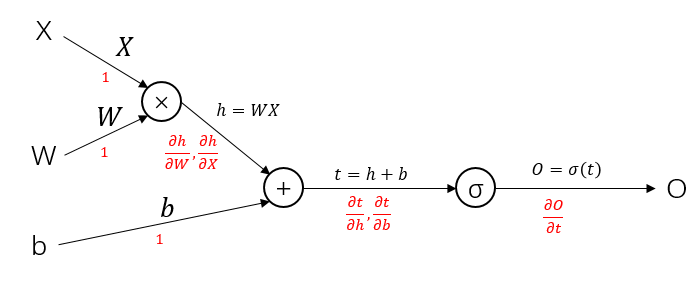
其中黑色为前向传播数据流,红色为反向传播每条边记录的当前位置的梯度。根据链式法则可以递归地从O开始反向计算任意一个变量的梯度,只需要连乘即可。例如:$\frac{\partial O}{\partial W} = \frac{\partial O}{\partial t} \frac{\partial t}{\partial h} \frac{\partial h}{\partial W}$。
计算图按照实现机制分为两类:
- 静态图,如TensorFlow
- 动态图,如Pytorch
早期TensorFlow使用的静态图需要在使用前定义图的结构,一旦定义好之后拓扑关系不能再改变。Pytorch使用动态图策略,在每次训练的循环中,计算图都被重新定义,但是保留每次迭代的参数状态(比如梯度信息)。
注:目前TensorFlow也可以使用tf.Gradient定义动态图了
Pytorch数据类型
张量底层结构
Pytorch中使用THTensor定义计算图中的数据结构,通过THTensor的运算自动构建运算图。为了节省内存开支,THTensor对象被设计成如下的结构:

- THTensor:记录维度、步长等描述性信息,此外包括THStorage指针
- THStorage:记录数据保存的内存分配
- Data:内存中真实的数据
对于一些操作,比如改变张量某个位置的值,或者是类似reshape一类的操作,得到不同的THTensor对象,但是它们共享相同的底层数据Data,从而节省了内存开支。
张量几个关键属性
假设我们有张量tensor,如下三个属性描述了张量的数据与交互:
tensor.data:张量的数据tensor.grad:张量的梯度tensor.grad_fn:张量由哪个函数计算而来,比如$tensor=\sigma (x)$,那么对应函数就是$\sigma(\bullet)$,可以通过调用tensor.grad_fn.next_functions遍历计算图节点
前向/反向传播一般编写流程
大致流程如下:
1 | # optimizer: 定义的优化器 |
Pytorch编写的动态图在连续迭代之间保留张量的梯度信息,如果不进行任何处理,新一轮迭代中计算的梯度会和之前积累的梯度相乘,如果使用每个batch的梯度更新,那么使用.zero_grad()方法清零之前的梯度。
高阶API
构建模型
继承torch.nn.Module类编写自己需要的模型/层/模块,或者一切可以描述成黑箱的计算过程。
模板:
1 | class MyNet(torch.nn.Module): |
由于在torch.nn.Module类中定义了__call__()方法回调forward(),因此继承得到的MyNet对象可以直接传递参数完成前向传播,比如:
1 | net = MyNet() |